2. Train from data¶
This notebook walks you through training a normalizing flow by gradient descent when data is available.
import matplotlib.pyplot as plt
import torch
import torch.utils.data as data
import zuko
_ = torch.random.manual_seed(0)
2.1. Dataset¶
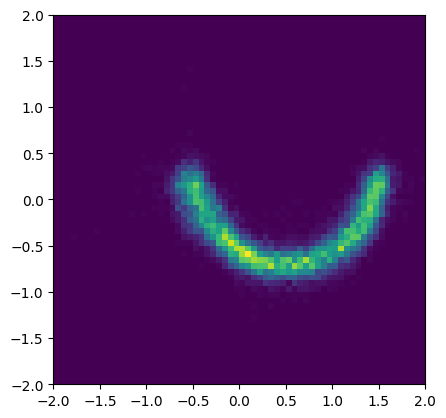
We consider the Two Moons dataset for demonstrative purposes.
def two_moons(n: int, sigma: float = 1e-1):
theta = 2 * torch.pi * torch.rand(n)
label = (theta > torch.pi).float()
x = torch.stack(
(
torch.cos(theta) + label - 1 / 2,
torch.sin(theta) + label / 2 - 1 / 4,
),
axis=-1,
)
return torch.normal(x, sigma), label
samples, labels = two_moons(16384)
plt.figure(figsize=(4.8, 4.8))
plt.hist2d(*samples.T, bins=64, range=((-2, 2), (-2, 2)))
plt.show()
trainset = data.TensorDataset(*two_moons(16384))
trainloader = data.DataLoader(trainset, batch_size=64, shuffle=True)
2.2. Unconditional flow¶
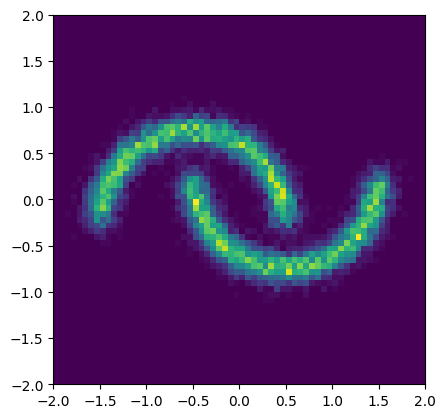
We use a neural spline flow (NSF) as density estimator \(q_\phi(x)\). The goal of the unconditional flow is to approximate the entire Two Moons distribution.
flow = zuko.flows.NSF(features=2, transforms=3, hidden_features=(64, 64))
flow
NSF(
(transform): LazyComposedTransform(
(0): MaskedAutoregressiveTransform(
(base): MonotonicRQSTransform(bins=8)
(order): [0, 1]
(hyper): MaskedMLP(
(0): MaskedLinear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): MaskedLinear(in_features=64, out_features=64, bias=True)
(3): ReLU()
(4): MaskedLinear(in_features=64, out_features=46, bias=True)
)
)
(1): MaskedAutoregressiveTransform(
(base): MonotonicRQSTransform(bins=8)
(order): [1, 0]
(hyper): MaskedMLP(
(0): MaskedLinear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): MaskedLinear(in_features=64, out_features=64, bias=True)
(3): ReLU()
(4): MaskedLinear(in_features=64, out_features=46, bias=True)
)
)
(2): MaskedAutoregressiveTransform(
(base): MonotonicRQSTransform(bins=8)
(order): [0, 1]
(hyper): MaskedMLP(
(0): MaskedLinear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): MaskedLinear(in_features=64, out_features=64, bias=True)
(3): ReLU()
(4): MaskedLinear(in_features=64, out_features=46, bias=True)
)
)
)
(base): UnconditionalDistribution(DiagNormal(loc: torch.Size([2]), scale: torch.Size([2])))
)
The objective is to minimize the Kullback-Leibler (KL) divergence between the true data distribution \(p(x)\) and the modeled distribution \(q_\phi(x)\).
\[\begin{split}
\begin{align}
\arg \min_\phi & ~ \mathrm{KL} \big( p(x) || q_\phi(x) \big) \\
= \arg \min_\phi & ~ \mathbb{E}_{p(x)} \left[ \log \frac{p(x)}{q_\phi(x)} \right] \\
= \arg \min_\phi & ~ \mathbb{E}_{p(x)} \big[ -\log q_\phi(x) \big]
\end{align}
\end{split}\]
optimizer = torch.optim.Adam(flow.parameters(), lr=1e-3)
for epoch in range(8):
losses = []
for x, label in trainloader:
loss = -flow().log_prob(x).mean()
loss.backward()
optimizer.step()
optimizer.zero_grad()
losses.append(loss.detach())
losses = torch.stack(losses)
print(f"({epoch})", losses.mean().item(), "±", losses.std().item())
(0) 1.385786771774292 ± 0.24798816442489624
(1) 1.1691052913665771 ± 0.09565525501966476
(2) 1.1397494077682495 ± 0.09650588035583496
(3) 1.121036171913147 ± 0.10365181416273117
(4) 1.1126291751861572 ± 0.09478515386581421
(5) 1.1063504219055176 ± 0.09685329347848892
(6) 1.1047922372817993 ± 0.0959908664226532
(7) 1.095753788948059 ± 0.0962706133723259
samples = flow().sample((16384,))
plt.figure(figsize=(4.8, 4.8))
plt.hist2d(*samples.T, bins=64, range=((-2, 2), (-2, 2)))
plt.show()
2.3. Conditional flow¶
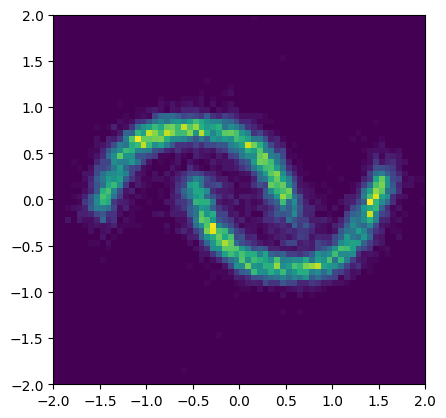
We use a conditional NSF as density estimator \(q_\phi(x | c)\), where \(c\) is the label indicating either the top or bottom moon of the Two Moons distribution.
flow = zuko.flows.NSF(features=2, context=1, transforms=3, hidden_features=(64, 64))
optimizer = torch.optim.Adam(flow.parameters(), lr=1e-3)
for epoch in range(8):
losses = []
for x, label in trainloader:
c = label.unsqueeze(dim=-1)
loss = -flow(c).log_prob(x).mean()
loss.backward()
optimizer.step()
optimizer.zero_grad()
losses.append(loss.detach())
losses = torch.stack(losses)
print(f"({epoch})", losses.mean().item(), "±", losses.std().item())
(0) 0.7310961484909058 ± 0.48028191924095154
(1) 0.41847169399261475 ± 0.10058867186307907
(2) 0.40901482105255127 ± 0.08987747877836227
(3) 0.39956235885620117 ± 0.09708698838949203
(4) 0.39864838123321533 ± 0.09798979759216309
(5) 0.39211612939834595 ± 0.10232935100793839
(6) 0.3830399215221405 ± 0.09735187143087387
(7) 0.37491780519485474 ± 0.10360059887170792
# sample from the flow conditioned on the top moon label
samples = flow(torch.tensor([0.0])).sample((16384,))
plt.figure(figsize=(4.8, 4.8))
plt.hist2d(*samples.T, bins=64, range=((-2, 2), (-2, 2)))
plt.show()
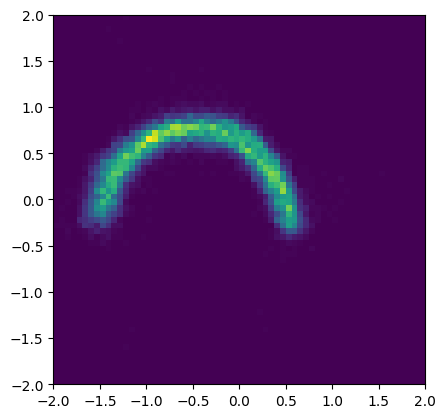
# sample from the flow conditioned on the bottom moon label
samples = flow(torch.tensor([1.0])).sample((16384,))
plt.figure(figsize=(4.8, 4.8))
plt.hist2d(*samples.T, bins=64, range=((-2, 2), (-2, 2)))
plt.show()